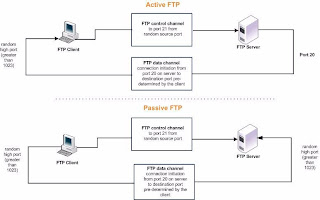
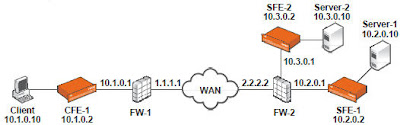
New CCIE Voice Locations in Asia
New CCIE Voice Locations in Asia In recognition of the demand for CCIE skills development in Asia, the CCIE program is pleased to announce new CCIE Voice lab exam test center openings in three major cities: Beijing Hong Kong Bangalore The CCIE program serves a growing number of worldwide candidates by covering all major regions with the latest test center resources. In addition to the three new locations, CCIE Voice lab exam locations include: San Jose RTP (North Carolina) Brussels Sydney Tokyo